 Cover figure
Cover figureAbstract
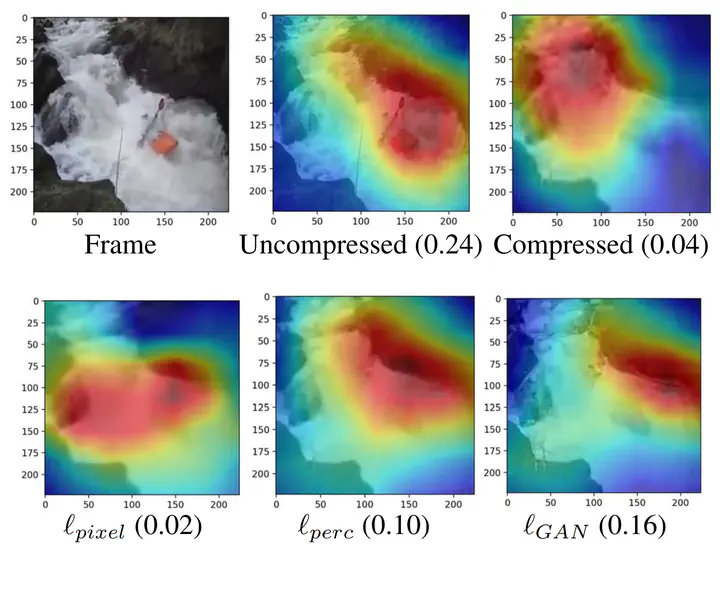
This paper studies the effect of quality degradation, caused by lossy video compression, on video recognition. We investigate how the state of the art video enhancement restores the video quality needed for an effective video recognition. Furthermore, we study the impact of various enhancement objectives, namely pixel-level, feature-level, and adversarial, on action recognition performance. Our experiments demonstrate that the models trained on pixellevel loss perform well in terms of visual quality but they hurt the accuracy of action recognition due to over smoothing discriminative features. On the other hand, models trained on perceptual and adversarial loss types not only generate better perceptual quality but also further improve the action recognition performance.