 Cover figure
Cover figureAbstract
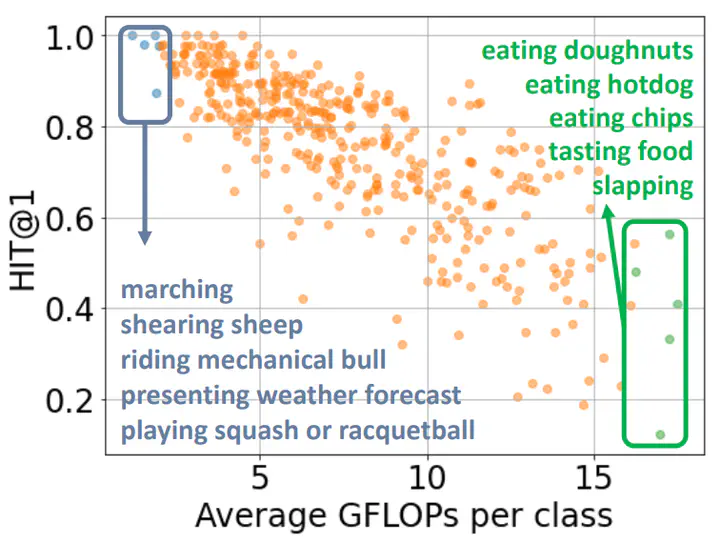
Video action classification and temporal localization are two key components of video understanding where we witnessed significant progress leveraging neural network architectures. Recently, the research focus in this area shifted towards computationally efficient solutions to support real-world applications. Existing methods mainly aim to pick salient frames or video clips with fixed architectures. As an alternative, here, we propose to learn policies to select the most efficient neural model conditioned on the given input video. Specifically, we train a novel model-selector offline with modelaffinity annotations that consolidate recognition quality and efficiency. Further, we incorporate the disparity between appearance and motion to estimate action background priors that enable efficient action localization without temporal annotations. To the best of our knowledge, this is the first attempt at computationally efficient action localization. We report classification results on two video benchmarks, Kinetics and multi-label HVU, and show that our method achieves state-of-the-art results while allowing a trade-off between accuracy and efficiency. For localization, we present evaluations on Thumos’14 and MultiThumos, where our approach improves or maintains the state-of-the-art performance while using only a fraction of the computation.