 Cover figure
Cover figureAbstract
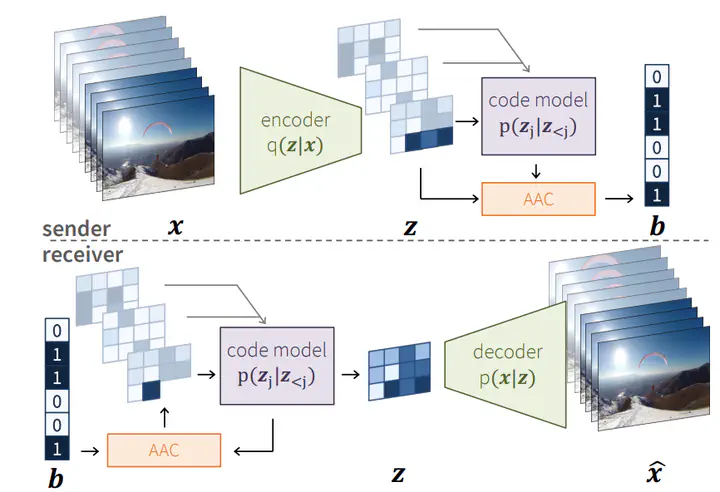
In this paper we present a a deep generative model for lossy video compression. We employ a model that consists of a 3D autoencoder with a discrete latent space and an autoregressive prior used for entropy coding. Both autoencoder and prior are trained jointly to minimize a rate-distortion loss, which is closely related to the ELBO used in variational autoencoders. Despite its simplicity, we find that our method outperforms the state-of-the-art learned video compression networks based on motion compensation or interpolation. We systematically evaluate various design choices, such as the use of frame-based or spatio-temporal autoencoders, and the type of autoregressive prior. In addition, we present three extensions of the basic method that demonstrate the benefits over classical approaches to compression. First, we introduce semantic compression, where the model is trained to allocate more bits to objects of interest. Second, we study adaptive compression, where the model is adapted to a domain with limited variability, e.g., videos taken from an autonomous car, to achieve superior compression on that domain. Finally, we introduce multimodal compression, where we demonstrate the effectiveness of our model in joint compression of multiple modalities captured by non-standard imaging sensors, such as quad cameras. We believe that this opens up novel video compression applications, which have not been feasible with classical codecs.