 Cover figure
Cover figureAbstract
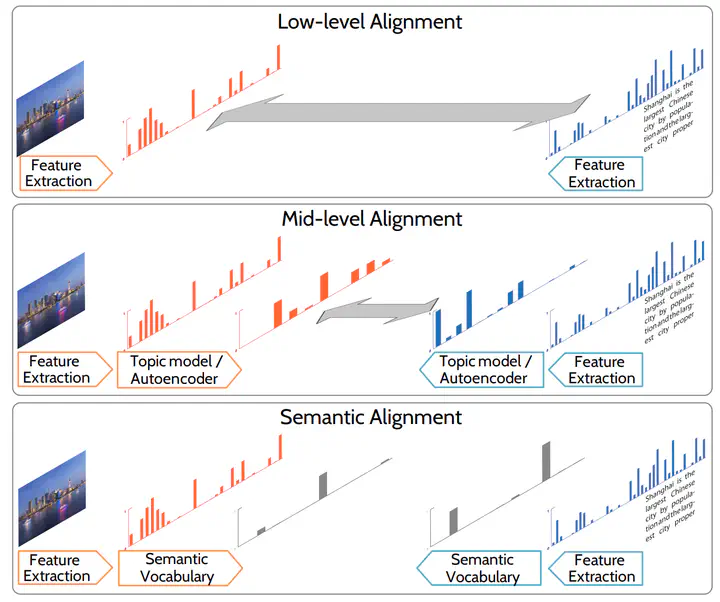
This paper proposes a data-driven approach for cross-media retrieval by automatically learning its underlying semantic vocabulary. Different from the existing semantic vocabularies, which are manually pre-defined and annotated, we automatically discover the vocabulary concepts and their annotations from multimedia collections. To this end, we apply a probabilistic topic model on the text available in the collection to extract its semantic structure. Moreover, we propose a learning to rank framework, to effectively learn the concept classifiers from the extracted annotations. We evaluate the discovered semantic vocabulary for cross-media retrieval on three datasets of image/text and video/text pairs. Our experiments demonstrate that the discovered vocabulary does not require any manual labeling to outperform three recent alternatives for cross-media retrieval.