 Cover figure
Cover figureAbstract
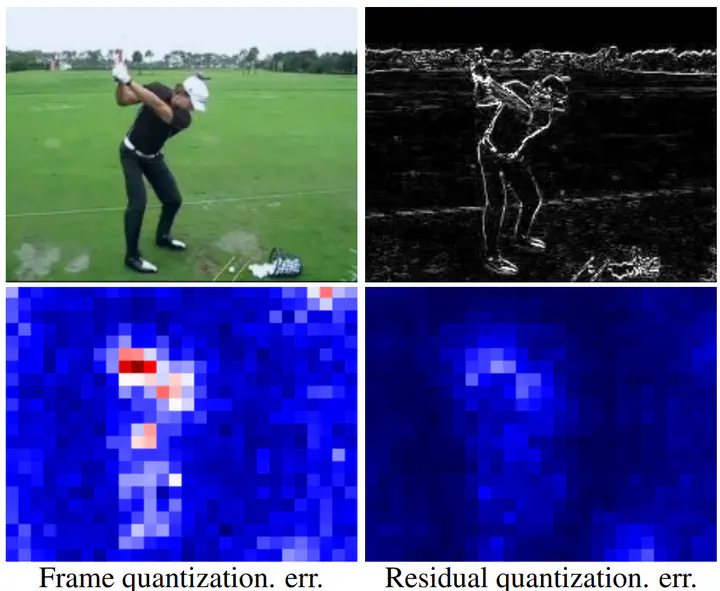
This paper accelerates video perception, such as semantic segmentation and human pose estimation, by levering cross-frame redundancies. Unlike the existing approaches, which avoid redundant computations by warping the past features using optical-flow or by performing sparse convolutions on frame differences, we approach the problem from a new perspective: low-bit quantization. We observe that residuals, as the difference in network activations between two neighboring frames, exhibit properties that make them highly quantizable. Based on this observation, we propose a novel quantization scheme for video networks coined as Residual Quantization. ResQ extends the standard, frame-by-frame, quantization scheme by incorporating temporal dependencies that lead to better performance in terms of accuracy vs. bit-width. Furthermore, we extend our model to dynamically adjust the bit-width proportional to the amount of changes in the video. We demonstrate the superiority of our model, against the standard quantization and existing efficient video perception models, using various architectures on semantic segmentation and human pose estimation benchmarks.