 Cover figure
Cover figureAbstract
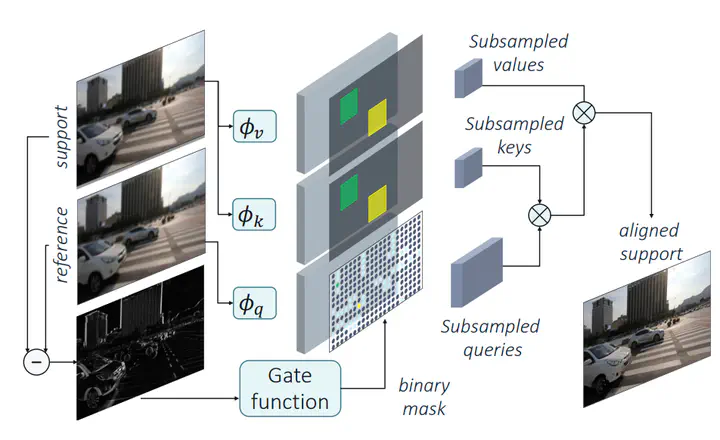
We tackle the task of efficient video super resolution. Motivated by our study on the quality vs. efficiency trade-off on a wide range of video super resolution architectures, we focus on the design of an efficient temporal alignment module, as it represents the major computational bottleneck in the current solutions. Our alignment module, named Gated Local Self Attention (GLSA), is based on a self-attention formulation and takes advantage of motion priors existing in the video to achieve a high efficiency. More specifically, we leverage the locality of motion in adjacent frames to aggregate information from a local neighborhood only. Moreover, we propose a gating module capable of learning binary functions over pixels, to restrict the alignment only to regions that undergo significant motion. We experimentally show the effectiveness of our proposed alignment on the commonly-used REDS and Vid4 datasets, reducing the overall computational cost by ∼13× and ∼2.8× respectively compared to state-of-the-art efficient video super-resolution networks.