Amir Habibian
Amir Habibian
Home
News
Publications
Talks
Light
Dark
Automatic
Publications
Type
Journal article
Conference paper
Date
2024
2023
2022
2021
2020
2019
2016
2015
2014
2013
Mobile Video Diffusion
Video diffusion models have achieved impressive realism and controllability but are limited by high computational demands, restricting …
Haitam Ben Yahia
,
Denis Korzhenkov
,
Ioannis Lelekas
,
Amir Ghodrati
,
Amir Habibian
PDF
Cite
Code
Project
MoViE: Mobile Diffusion for Video Editing
Recent progress in diffusion-based video editing has shown remarkable potential for practical applications. However, these methods …
Adil Karjauv
,
Noor Fathima
,
Ioannis Lelekas
,
Fatih Porikli
,
Amir Ghodrati
,
Amir Habibian
PDF
Cite
Code
Project
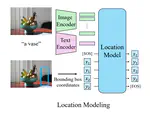
Generative Location Modeling for Spatially Aware Object Insertion
Generative models have become a powerful tool for image editing tasks, including object insertion. However, these methods often lack …
Jooyeol Yun
,
Davide Abati
,
Mohamed Omran
,
Jaegul Choo
,
Amir Habibian
,
Auke Wiggers
PDF
Cite
Project
Object-Centric Diffusion for Efficient Video Editing
Diffusion-based video editing have reached impressive quality and can transform either the global style, local structure, and …
Kumara Kahatapitiya
,
Adil Karjauv
,
Davide Abati
,
Fatih Porikli
,
Yuki Asano
,
Amir Habibian
PDF
Cite
Project
Clockwork Diffusion: Efficient Generation With Model-Step Distillation
This work aims to improve the efficiency of text-to-image diffusion models. While diffusion models use computationally expensive …
Amir Habibian
,
Amir Ghodrati
,
Noor Fathima
,
Guillaume Sautiere
,
Risheek Garrepalli
,
Fatih Porikli
,
Jens Petersen
PDF
Cite
Code
Project
VaLID: Variable-Length Input Diffusion for Novel View Synthesis
Novel View Synthesis (NVS), which tries to produce a realistic image at the target view given source view images and their …
Shijie Li
,
Farhad G Zanjani
,
Haitam Ben Yahia
,
Yuki M Asano
,
Juergen Gall
,
Amir Habibian
PDF
Cite
ResQ: Residual Quantization for Video Perception
This paper accelerates video perception, such as semantic segmentation and human pose estimation, by levering cross-frame redundancies. …
Davide Abati
,
Haitam Ben Yahia
,
Markus Nagel
,
Amir Habibian
PDF
Cite
Skip-Attention: Improving Vision Transformers by Paying Less Attention
This work aims to improve the efficiency of vision transformers (ViT). While ViTs use computationally expensive self-attention …
Shashanka Venkataramanan
,
Amir Ghodrati
,
Yuki M Asano
,
Fatih Porikli
,
Amir Habibian
PDF
Cite
SALISA: Saliency-Based Input Sampling for Efficient Video Object Detection
High-resolution images are widely adopted for high-performance object detection in videos. However, processing high-resolution inputs …
Babak Ehteshami Bejnordi
,
Amir Habibian
,
Fatih Porikli
,
Amir Ghodrati
PDF
Cite
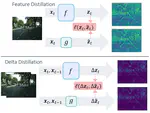
Delta Distillation for Efficient Video Processing
This paper aims to accelerate video stream processing, such as object detection and semantic segmentation, by leveraging the temporal …
Amir Habibian
,
Haitam Ben Yahia
,
Davide Abati
,
Efstratios Gavves
,
Fatih Porikli
PDF
Cite
Code
Simple and Efficient Architectures for Semantic Segmentation
Though the state-of-the architectures for semantic segmentation, such as HRNet, demonstrate impressive accuracy, the complexity arising …
Dushyant Mehta
,
Andrii Skliar
,
Haitam Ben Yahia
,
Shubhankar Borse
,
Fatih Porikli
,
Amir Habibian
,
Tijmen Blankevoort
PDF
Cite
Code
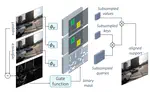
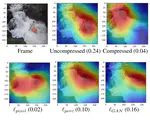
Region-of-Interest based Neural Video Compression
Humans do not perceive all parts of a scene with the same resolution, but rather focus on few regions of interest (ROIs). Traditional …
Yura Perugachi-Diaz
,
Guillaume Sautiere
,
Davide Abati
,
Yang Yang
,
Amir Habibian
,
Taco S Cohen
PDF
Cite
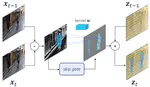
Skip-Convolutions for Efficient Video Processing
We propose Skip-Convolutions to leverage the large amount of redundancies in video streams and save computations. Each video is …
Amir Habibian
,
Davide Abati
,
Taco S Cohen
,
Babak Ehteshami Bejnordi
PDF
Cite
Code
Frame-Exit: Conditional Early Exiting for Efficient Video Recognition
In this paper, we propose a conditional early exiting framework for efficient video recognition. While existing works focus on …
Amir Ghodrati
,
Babak Ehteshami Bejnordi
,
Amir Habibian
PDF
Cite
Code
Efficient Video Super Resolution by Gated Local Self Attention
We tackle the task of efficient video super resolution. Motivated by our study on the quality vs. efficiency trade-off on a wide range …
Davide Abati
,
Amir Ghodrati
,
Amir Habibian
PDF
Cite
Conditional Model Selection for Efficient Video Understanding
Video action classification and temporal localization are two key components of video understanding where we witnessed significant …
Mihir Jain
,
Haitam Ben Yahia
,
Amir Ghodrati
,
Fatih Porikli
,
Amir Habibian
PDF
Cite
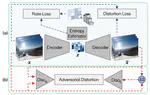
Adversarial Distortion for Learned Video Compression
In this paper, we present a novel adversarial lossy video compression model. At extremely low bit-rates, standard video coding schemes …
Vijay Veerabadran
,
Reza Pourreza
,
Amir Habibian
,
Taco S Cohen
PDF
Cite
Learning Variations in Human Motion via Mix-and-Match Perturbation
Human motion prediction is a stochastic process: Given an observed sequence of poses, multiple future motions are plausible. Existing …
Mohammad Sadegh Aliakbarian
,
Fatemeh Sadat Saleh
,
Mathieu Salzmann
,
Lars Petersson
,
Stephen Gould
,
Amir Habibian
PDF
Cite
Code
Recognizing Compressed Videos: Challenges and Promises
This paper studies the effect of quality degradation, caused by lossy video compression, on video recognition. We investigate how the …
Reza Pourreza
,
Amir Ghodrati
,
Amir Habibian
PDF
Cite
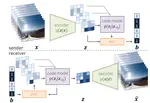
Video Compression with Rate-Distortion Autoencoders
In this paper we present a a deep generative model for lossy video compression. We employ a model that consists of a 3D autoencoder …
Amir Habibian
,
Ties van Rozendaal
,
Jakub M Tomczak
,
Taco S Cohen
PDF
Cite
Video2vec Embeddings Recognize Events when Examples are Scarce
This paper aims for event recognition when video examples are scarce or even completely absent. The key in such a challenging setting …
Amir Habibian
,
Thomas Mensink
,
Cees GM Snoek
PDF
Cite
Discovering Semantic Vocabularies for Cross-Media Retrieval
This paper proposes a data-driven approach for cross-media retrieval by automatically learning its underlying semantic vocabulary. …
Amir Habibian
,
Thomas Mensink
,
Cees GM Snoek
PDF
Cite
Videostory: A New Multimedia Embedding for Few-Example Recognition and Translation of Events
This paper proposes a data-driven approach for cross-media retrieval by automatically learning its underlying semantic vocabulary. …
Amir Habibian
,
Thomas Mensink
,
Cees GM Snoek
PDF
Cite
Recommendations for recognizing video events by concept vocabularies
Representing videos using vocabularies composed of concept detectors appears promising for generic event recognition. While many have …
Amir Habibian
,
Cees GM Snoek
PDF
Cite
Composite Concept Discovery for Zero-shot Video Event Detection
R We consider automated detection of events in video without the use of any visual training examples. A common approach is to represent …
Amir Habibian
,
Thomas Mensink
,
Cees GM Snoek
PDF
Cite
Recommendations for Video Event Recognition using Concept Vocabularies
Representing videos using vocabularies composed of concept detectors appears promising for event recognition. While many have recently …
Amirhossein Habibian
,
Koen EA van de Sande
,
Cees GM Snoek
PDF
Cite
Cite
×